Abstract
Building cross-modal applications is challenging due to limited paired multi-modal data. Recent works have shown that leveraging a pre-trained multi-modal contrastive representation space enables cross-modal tasks to be learned from uni-modal data. This is based on the assumption that contrastive optimization makes embeddings from different modalities interchangeable. However, this assumption is under-explored due to the poorly understood geometry of the multi-modal contrastive space, where a modality gap exists. In our study, we provide a theoretical explanation of this space's geometry and introduce a three-step method, C3 (Connect, Collapse, Corrupt), to bridge the modality gap, enhancing the interchangeability of embeddings. Our C3 method significantly improves cross-modal learning from uni-modal data, achieving state-of-the-art results on zero-shot image / audio / video captioning and text-to-image generation.
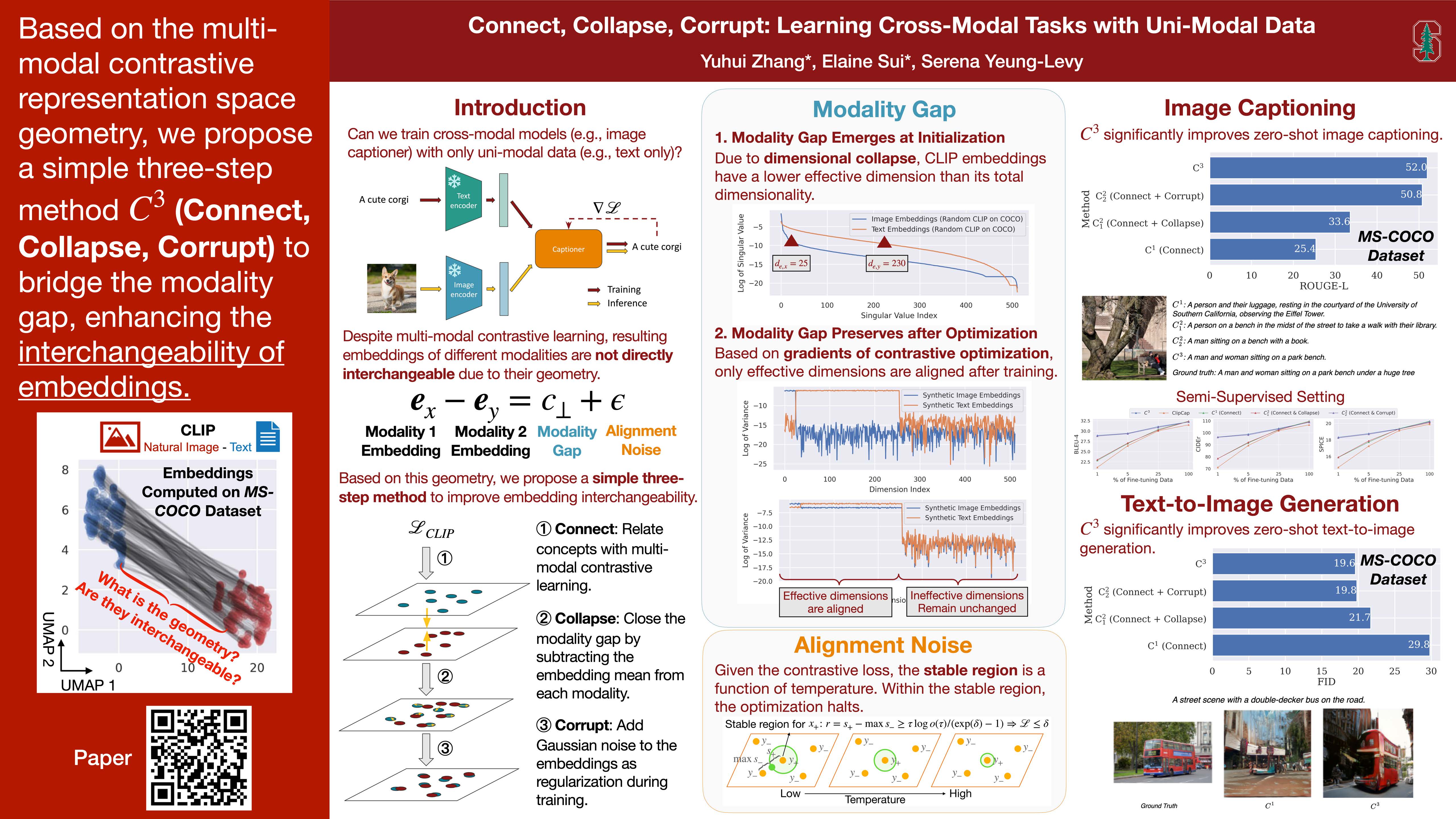
💡 Motivation of Our Approach
Our work provides a theoretical explanation of the unique geometry that arises from multi-modal contrastive learning, where a modality gap and alignment noise exist in the learned representation space (check out this in the paper!). Building upon this understanding, we present a straightforward technique, C3, which enhances the interchangeability of embeddings between modalities, enabling the creation of cross-modal applications using only uni-modal data.
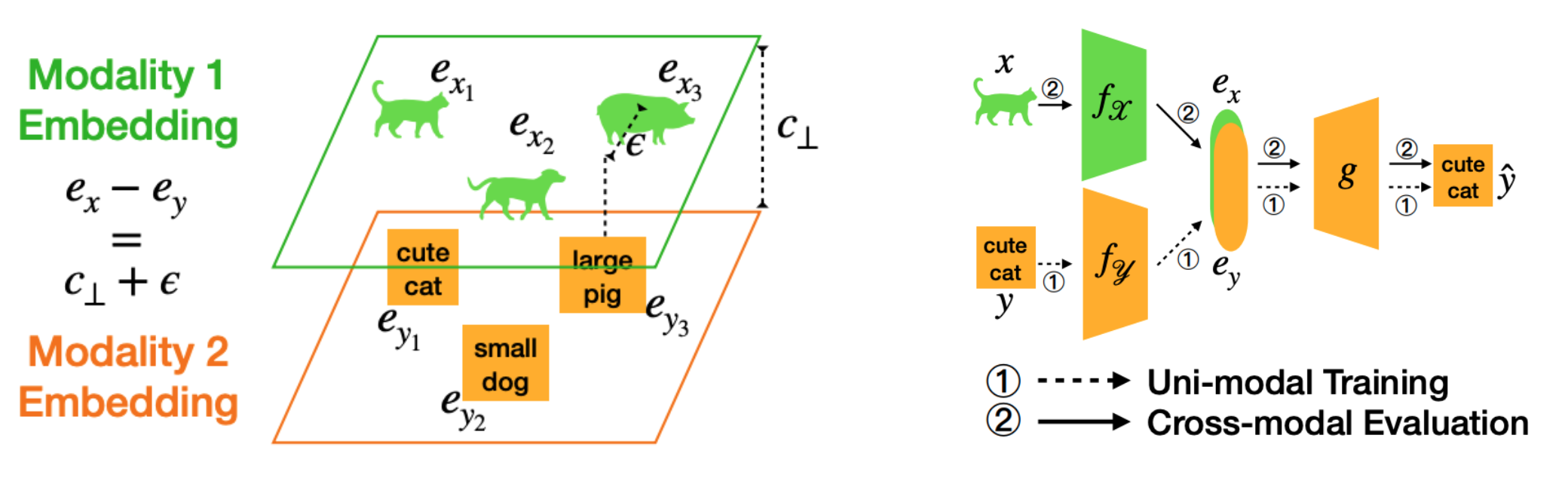
🔮 C3: Connect, Collapse, Corrupt
C3 improves the interchangeability of embeddings from different modalities with three steps: connect (related concepts from different modalities are connected via multi-modal contrastive learning), collapse (eliminate the most dominant distributional difference by closing the modality gap), corrupt (additional noise is introduced as regularization during training).

📈 Results
We apply C3 to many applications: zero-shot image / audio / video captioning and text-to-image generation.
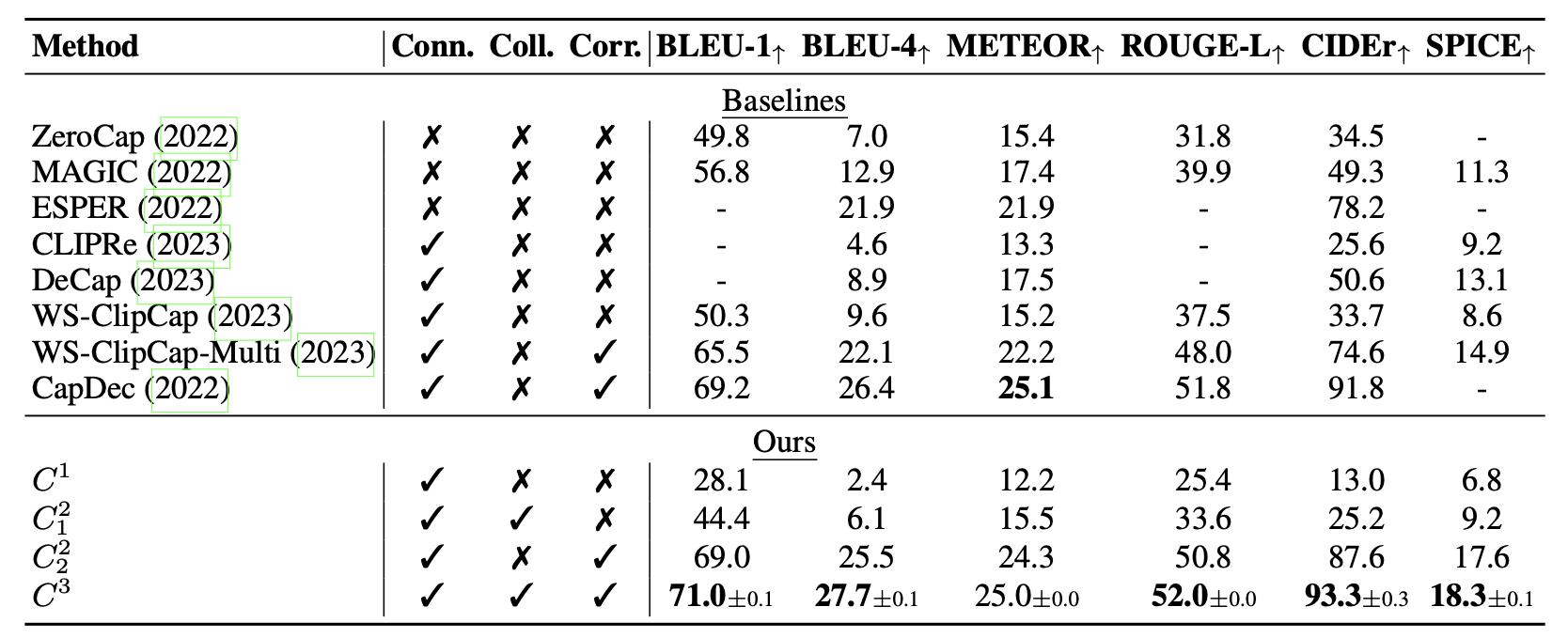
Image Captioning
Image-free image-to-text captioning results. We achieve state-of-the-art zero-shot image captioning and our ablation shows the effectiveness of each component in our method C3.

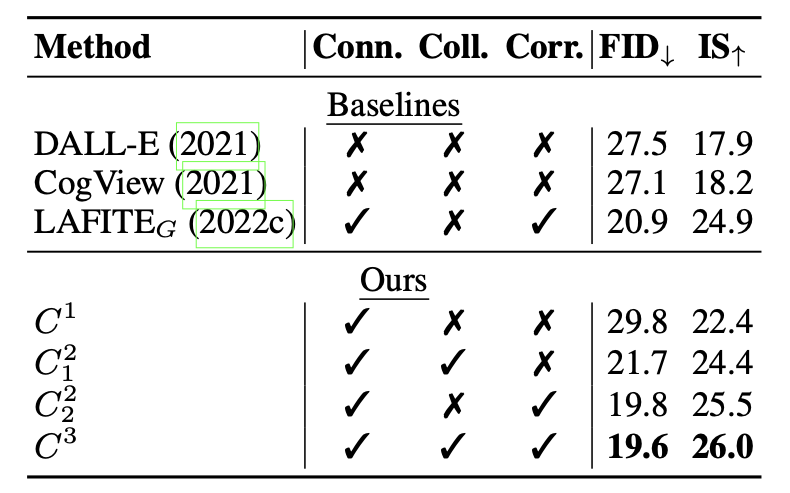
Text-to-Image Generation
Language-free text-to-image generation results. Our method C3 consistently outperforms the baselines.

Generalization to Other Modalities, Datasets, and Contrastive Embedding Spaces
C3 consistently improves baselines in all the settings.

BibTeX
@inproceedings{C3,
title={Connect, Collapse, Corrupt: Learning Cross-Modal Tasks with Uni-Modal Data},
author={Zhang, Yuhui and Sui, Elaine and Yeung-Levy, Serena},
booktitle={International Conference on Learning Representations (ICLR)},
year={2024}
}